You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The AI Thread
- Thread starter Truthy
- Start date
AI ‘breakthrough’: neural net has human-like ability to generalize language
Scientists have created a neural network with the human-like ability to make generalizations about language. The artificial intelligence (AI) system performs about as well as humans at folding newly learned words into an existing vocabulary and using them in fresh contexts, which is a key aspect of human cognition known as systematic generalization.
The researchers gave the same task to the AI model that underlies the chatbot ChatGPT, and found that it performs much worse on such a test than either the new neural net or people, despite the chatbot’s uncanny ability to converse in a human-like manner.
Systematic generalization is demonstrated by people’s ability to effortlessly use newly acquired words in new settings. For example, once someone has grasped the meaning of the word ‘photobomb’, they will be able to use it in a variety of situations, such as ‘photobomb twice’ or ‘photobomb during a Zoom call’. Similarly, someone who understands the sentence ‘the cat chases the dog’ will also understand ‘the dog chases the cat’ without much extra thought.
But this ability does not come innately to neural networks, a method of emulating human cognition that has dominated artificial-intelligence research, says Brenden Lake, a cognitive computational scientist at New York University and co-author of the study. Unlike people, neural nets struggle to use a new word until they have been trained on many sample texts that use that word. Artificial-intelligence researchers have sparred for nearly 40 years as to whether neural networks could ever be a plausible model of human cognition if they cannot demonstrate this type of systematicity.
To attempt to settle this debate, the authors first tested 25 people on how well they deploy newly learnt words to different situations. The researchers ensured the participants would be learning the words for the first time by testing them on a pseudo-language consisting of two categories of nonsense words. ‘Primitive’ words such as ‘dax,’ ‘wif’ and ‘lug’ represented basic, concrete actions such as ‘skip’ and ‘jump’. More abstract ‘function’ words such as ‘blicket’, ‘kiki’ and ’fep’ specified rules for using and combining the primitives, resulting in sequences such as ‘jump three times’ or ‘skip backwards’.
Participants were trained to link each primitive word with a circle of a particular colour, so a red circle represents ‘dax’, and a blue circle represents ‘lug’. The researchers then showed the participants combinations of primitive and function words alongside the patterns of circles that would result when the functions were applied to the primitives. For example, the phrase ‘dax fep’ was shown with three red circles, and ‘lug fep’ with three blue circles, indicating that fep denotes an abstract rule to repeat a primitive three times.
Finally, the researchers tested participants’ ability to apply these abstract rules by giving them complex combinations of primitives and functions. They then had to select the correct colour and number of circles and place them in the appropriate order.
As predicted, people excelled at this task; they chose the correct combination of coloured circles about 80% of the time, on average. When they did make errors, the researchers noticed that these followed a pattern that reflected known human biases.
Next, the researchers trained a neural network to do a task similar to the one presented to participants, by programming it to learn from its mistakes. This approach allowed the AI to learn as it completed each task rather than using a static data set, which is the standard approach to training neural nets. To make the neural net human-like, the authors trained it to reproduce the patterns of errors they observed in humans’ test results. When the neural net was then tested on fresh puzzles, its answers corresponded almost exactly to those of the human volunteers, and in some cases exceeded their performance.
By contrast, GPT-4 struggled with the same task, failing, on average, between 42 and 86% of the time, depending on how the researchers presented the task. “It’s not magic, it’s practice,” Lake says. “Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.”
Melanie Mitchell, a computer and cognitive scientist at the Santa Fe Institute in New Mexico, says this study is an interesting proof of principle, but it remains to be seen if this training method can scale up to generalize across a much larger data set or even to images. Lake hopes to tackle this problem by studying how people develop a knack for systematic generalization from a young age, and incorporating those findings to build a more robust neural net.
Elia Bruni, a specialist in natural language processing at the University of Osnabrück in Germany, says this research could make neural networks more-efficient learners. This would reduce the gargantuan amount of data necessary to train systems such as ChatGPT and would minimize ‘hallucination’, which occurs when AI perceives patterns that are non-existent and creates inaccurate outputs. “Infusing systematicity into neural networks is a big deal,” Bruni says. “It could tackle both these issues at the same time.”

Writeup Paper
Scientists have created a neural network with the human-like ability to make generalizations about language. The artificial intelligence (AI) system performs about as well as humans at folding newly learned words into an existing vocabulary and using them in fresh contexts, which is a key aspect of human cognition known as systematic generalization.
The researchers gave the same task to the AI model that underlies the chatbot ChatGPT, and found that it performs much worse on such a test than either the new neural net or people, despite the chatbot’s uncanny ability to converse in a human-like manner.
Systematic generalization is demonstrated by people’s ability to effortlessly use newly acquired words in new settings. For example, once someone has grasped the meaning of the word ‘photobomb’, they will be able to use it in a variety of situations, such as ‘photobomb twice’ or ‘photobomb during a Zoom call’. Similarly, someone who understands the sentence ‘the cat chases the dog’ will also understand ‘the dog chases the cat’ without much extra thought.
But this ability does not come innately to neural networks, a method of emulating human cognition that has dominated artificial-intelligence research, says Brenden Lake, a cognitive computational scientist at New York University and co-author of the study. Unlike people, neural nets struggle to use a new word until they have been trained on many sample texts that use that word. Artificial-intelligence researchers have sparred for nearly 40 years as to whether neural networks could ever be a plausible model of human cognition if they cannot demonstrate this type of systematicity.
To attempt to settle this debate, the authors first tested 25 people on how well they deploy newly learnt words to different situations. The researchers ensured the participants would be learning the words for the first time by testing them on a pseudo-language consisting of two categories of nonsense words. ‘Primitive’ words such as ‘dax,’ ‘wif’ and ‘lug’ represented basic, concrete actions such as ‘skip’ and ‘jump’. More abstract ‘function’ words such as ‘blicket’, ‘kiki’ and ’fep’ specified rules for using and combining the primitives, resulting in sequences such as ‘jump three times’ or ‘skip backwards’.
Participants were trained to link each primitive word with a circle of a particular colour, so a red circle represents ‘dax’, and a blue circle represents ‘lug’. The researchers then showed the participants combinations of primitive and function words alongside the patterns of circles that would result when the functions were applied to the primitives. For example, the phrase ‘dax fep’ was shown with three red circles, and ‘lug fep’ with three blue circles, indicating that fep denotes an abstract rule to repeat a primitive three times.
Finally, the researchers tested participants’ ability to apply these abstract rules by giving them complex combinations of primitives and functions. They then had to select the correct colour and number of circles and place them in the appropriate order.
As predicted, people excelled at this task; they chose the correct combination of coloured circles about 80% of the time, on average. When they did make errors, the researchers noticed that these followed a pattern that reflected known human biases.
Next, the researchers trained a neural network to do a task similar to the one presented to participants, by programming it to learn from its mistakes. This approach allowed the AI to learn as it completed each task rather than using a static data set, which is the standard approach to training neural nets. To make the neural net human-like, the authors trained it to reproduce the patterns of errors they observed in humans’ test results. When the neural net was then tested on fresh puzzles, its answers corresponded almost exactly to those of the human volunteers, and in some cases exceeded their performance.
By contrast, GPT-4 struggled with the same task, failing, on average, between 42 and 86% of the time, depending on how the researchers presented the task. “It’s not magic, it’s practice,” Lake says. “Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.”
Melanie Mitchell, a computer and cognitive scientist at the Santa Fe Institute in New Mexico, says this study is an interesting proof of principle, but it remains to be seen if this training method can scale up to generalize across a much larger data set or even to images. Lake hopes to tackle this problem by studying how people develop a knack for systematic generalization from a young age, and incorporating those findings to build a more robust neural net.
Elia Bruni, a specialist in natural language processing at the University of Osnabrück in Germany, says this research could make neural networks more-efficient learners. This would reduce the gargantuan amount of data necessary to train systems such as ChatGPT and would minimize ‘hallucination’, which occurs when AI perceives patterns that are non-existent and creates inaccurate outputs. “Infusing systematicity into neural networks is a big deal,” Bruni says. “It could tackle both these issues at the same time.”
Spoiler Legend :
a, During training, episode a presents a neural network with a set of study examples and a query instruction, all provided as a simultaneous input. The study examples demonstrate how to ‘jump twice’, ‘skip’ and so on with both instructions and corresponding outputs provided as words and text-based action symbols (solid arrows guiding the stick figures), respectively. The query instruction involves compositional use of a word (‘skip’) that is presented only in isolation in the study examples, and no intended output is provided. The network produces a query output that is compared (hollow arrows) with a behavioural target. b, Episode b introduces the next word (‘tiptoe’) and the network is asked to use it compositionally (‘tiptoe backwards around a cone’), and so on for many more training episodes. The colours highlight compositional reuse of words. Stick figures were adapted from art created by D. Chappard (OpenClipArt.org).
Writeup Paper
Biden has made some rules for AI, but they only apply if the model is 1,000 times bigger than ChatGPT? Did someone get the decimal point in the wrong place?
The White House wants to know who is deploying AI compute clusters and training large language models — but for now only the really, really, big ones.
So far the White House has only set interim thresholds that trigger reporting obligations.
One requires reporting of any model trained using more than 10^26 integer or floating point operations total, or more than 10^23 floating point operations for biological sequence data.
The second sets a threshold for compute clusters located in a single datacenter and networked at more than 100Gb/s. Facilities exceeding 10^20 FLOPS of AI training capacity in that second case will be subject to reporting rules.
That 10^20 FLOPS figure translates to 100 exaFLOPS, which is a lot for one datacenter. Meanwhile the 10^26 figure is the cumulative number of operations used to train a model over a period of time and would be equivalent to a total of 100 million quintillion floating point operations.
Researchers at University of California, Berkeley estimate OpenAI's GPT-3 required about 3.1 x 10^23 floating-point operations of compute to train the full 175 billion parameter model.
By our estimate, individual models that meet the administration’s reporting threshold would employ a cluster of 10,000 Nvidia H100s running at their lowest precision with sparsity for about a month. However, many popular large language models, such as GPT-3, were trained at higher precision, which changes the math a bit. Using FP32, that same cluster would need to be run for 7.5 months to reach that limit.
The reporting requirement for AI datacenters is just as eyebrow raising, working out to 100 exaFLOPs. Note that neither rule addresses whether those limits are for FP8 calculations or FP64. As we've previously discussed 1 exaFLOPS at FP64 isn't the same as an 1 exaFLOPS at FP32 or FP8. Context matters.
Going back to the H100, you'd need a facility with about 25,000 of the Nvidia GPUs — each good for 3,958 teraFLOPS of sparse FP8 performance, to meet the reporting requirement. However, if you've deployed something like AMD's Instinct MI250X, which doesn't support FP8, you'd need 261,097 GPUs before the Biden administration wants you to fill in its reporting paperwork.
The Register is aware of H100 deployments at that scale. GPU-centric cloud operator CoreWeave has deployed about 22,000 H100s. AI infrastructure startup Voltage Park plans to deploy 24,000 H100s. However neither outfit puts all its GPUs in a single datacenter, so might not exceed the reporting threshold.
The White House wants to know who is deploying AI compute clusters and training large language models — but for now only the really, really, big ones.
So far the White House has only set interim thresholds that trigger reporting obligations.
One requires reporting of any model trained using more than 10^26 integer or floating point operations total, or more than 10^23 floating point operations for biological sequence data.
The second sets a threshold for compute clusters located in a single datacenter and networked at more than 100Gb/s. Facilities exceeding 10^20 FLOPS of AI training capacity in that second case will be subject to reporting rules.
That 10^20 FLOPS figure translates to 100 exaFLOPS, which is a lot for one datacenter. Meanwhile the 10^26 figure is the cumulative number of operations used to train a model over a period of time and would be equivalent to a total of 100 million quintillion floating point operations.
Researchers at University of California, Berkeley estimate OpenAI's GPT-3 required about 3.1 x 10^23 floating-point operations of compute to train the full 175 billion parameter model.
By our estimate, individual models that meet the administration’s reporting threshold would employ a cluster of 10,000 Nvidia H100s running at their lowest precision with sparsity for about a month. However, many popular large language models, such as GPT-3, were trained at higher precision, which changes the math a bit. Using FP32, that same cluster would need to be run for 7.5 months to reach that limit.
The reporting requirement for AI datacenters is just as eyebrow raising, working out to 100 exaFLOPs. Note that neither rule addresses whether those limits are for FP8 calculations or FP64. As we've previously discussed 1 exaFLOPS at FP64 isn't the same as an 1 exaFLOPS at FP32 or FP8. Context matters.
Going back to the H100, you'd need a facility with about 25,000 of the Nvidia GPUs — each good for 3,958 teraFLOPS of sparse FP8 performance, to meet the reporting requirement. However, if you've deployed something like AMD's Instinct MI250X, which doesn't support FP8, you'd need 261,097 GPUs before the Biden administration wants you to fill in its reporting paperwork.
The Register is aware of H100 deployments at that scale. GPU-centric cloud operator CoreWeave has deployed about 22,000 H100s. AI infrastructure startup Voltage Park plans to deploy 24,000 H100s. However neither outfit puts all its GPUs in a single datacenter, so might not exceed the reporting threshold.
EnglishEdward
Deity
Thank you.
So it is all just a dead cat/red herring or whatever, Biden just followed instructions from the corporates not to do anything meaningful.
And I dare say that the Trump would have just played another round of golf.
So it is all just a dead cat/red herring or whatever, Biden just followed instructions from the corporates not to do anything meaningful.
And I dare say that the Trump would have just played another round of golf.
DeepMind AI accurately forecasts weather — on a desktop computer
Artificial-intelligence (AI) firm Google DeepMind has turned its hand to the intensive science of weather forecasting — and developed a machine-learning model that outperforms the best conventional tools as well as other AI approaches at the task.
The model, called GraphCast, can run from a desktop computer and makes more accurate predictions than conventional models in minutes rather than hours.
“GraphCast currently is leading the race amongst the AI models,” says computer scientist Aditya Grover at University of California, Los Angeles. The model is described in Science on 14 November.
Predicting the weather is a complex and energy-intensive task. The standard approach is called numerical weather prediction (NWP), which uses mathematical models based on physical principles. These tools, known as physical models, crunch weather data from buoys, satellites and weather stations worldwide using supercomputers. The calculations accurately map out how heat, air and water vapour move through the atmosphere, but they are expensive and energy-intensive to run.
To reduce the financial and energy cost of forecasting, several technology companies have developed machine-learning models that rapidly predict the future state of global weather from past and current weather data. Among them are DeepMind, computer chip-maker Nvidia and Chinese tech company Huawei, alongside a slew of start-ups such as Atmo based in Berkeley, California. Of these, Huawei’s Pangu-weather model is the strongest rival to the gold-standard NWP system at the European Centre for Medium-Range Weather Forecasts (ECMWF) in Reading, UK, which provides world-leading weather predictions up to 15 days in advance.
Machine learning is spurring a revolution in weather forecasting, says Matthew Chantry at the ECMWF. AI models run 1,000 to 10,000 times faster than conventional NWP models, leaving more time for interpreting and communicating predictions, says data-visualization researcher Jacob Radford, at the Cooperative Institute for Research in the Atmosphere in Colorado.
GraphCast, developed by Google’s AI company DeepMind in London, outperforms conventional and AI-based approaches at most global weather-forecasting tasks. Researchers first trained the model using estimates of past global weather made from 1979 to 2017 by physical models. This allowed GraphCast to learn links between weather variables such as air pressure, wind, temperature and humidity.
The trained model uses the ‘current’ state of global weather and weather estimates from 6 hours earlier to predict the weather 6 hours ahead. Earlier predictions are fed back into the model, enabling it to make estimates further into the future. DeepMind researchers found that GraphCast could use global weather estimates from 2018 to make forecasts up to 10 days ahead in less than a minute, and the predictions were more accurate than the ECMWF’s High RESolution forecasting system (HRES) — one version of its NWP — which takes hours to forecast.
“In the troposphere, which is the part of the atmosphere closest to the surface that affects us all the most, GraphCast outperforms HRES on more than 99% of the 12,00 measurements that we’ve done,” says computer scientist Remi Lam at DeepMind in London. Across all levels of the atmosphere, the model outperformed HRES on 90% of weather predictions.
GraphCast predicted the state of 5 weather variables close to the Earth’s surface, such as the air temperature 2-metres above the ground, and 6 atmospheric variables, such as wind speed, further from the Earth’s surface.
It also proved useful in predicting severe weather events, such as the paths taken by tropical cyclones, and extreme heat and cold episodes, says Chantry.
When they compared the forecasting ability of GraphCast with Pangu-weather, the DeepMind researchers found that their model beat 99% of weather predictions that had been described in a previous Huawei study.
Chantry notes that although GraphCast’s performance was superior to other models in this study, based on its evaluation by certain metrics, future assessments of its performance using other metrics could lead to slightly different results.
Rather than entirely replacing conventional approaches, machine-learning models, which are still experimental, could boost particular types of weather prediction that standard approaches aren’t good at, says Chantry — such as forecasting rainfall that will hit the ground within a few hours.
“And standard physical models are still needed to provide the estimates of global weather that are initially used to train machine-learning models,” says Chantry. “I anticipate it will be another two to five years before people can use forecasting from machine learning approaches to make decisions in the real-world,” he adds.
In the meantime, problems with machine-learning approaches must be ironed out. Unlike NWP models, researchers cannot fully understand how AIs such as GraphCast work because the decision-making processes happen in AI’s ‘black box’, says Grover. “This calls into question their reliability,” she says.
AI models also run the risk of amplifying biases in their training data and require a lot of energy for training, although they consume less energy than NWP models, says Grover.
Artificial-intelligence (AI) firm Google DeepMind has turned its hand to the intensive science of weather forecasting — and developed a machine-learning model that outperforms the best conventional tools as well as other AI approaches at the task.
The model, called GraphCast, can run from a desktop computer and makes more accurate predictions than conventional models in minutes rather than hours.
“GraphCast currently is leading the race amongst the AI models,” says computer scientist Aditya Grover at University of California, Los Angeles. The model is described in Science on 14 November.
Predicting the weather is a complex and energy-intensive task. The standard approach is called numerical weather prediction (NWP), which uses mathematical models based on physical principles. These tools, known as physical models, crunch weather data from buoys, satellites and weather stations worldwide using supercomputers. The calculations accurately map out how heat, air and water vapour move through the atmosphere, but they are expensive and energy-intensive to run.
To reduce the financial and energy cost of forecasting, several technology companies have developed machine-learning models that rapidly predict the future state of global weather from past and current weather data. Among them are DeepMind, computer chip-maker Nvidia and Chinese tech company Huawei, alongside a slew of start-ups such as Atmo based in Berkeley, California. Of these, Huawei’s Pangu-weather model is the strongest rival to the gold-standard NWP system at the European Centre for Medium-Range Weather Forecasts (ECMWF) in Reading, UK, which provides world-leading weather predictions up to 15 days in advance.
Machine learning is spurring a revolution in weather forecasting, says Matthew Chantry at the ECMWF. AI models run 1,000 to 10,000 times faster than conventional NWP models, leaving more time for interpreting and communicating predictions, says data-visualization researcher Jacob Radford, at the Cooperative Institute for Research in the Atmosphere in Colorado.
GraphCast, developed by Google’s AI company DeepMind in London, outperforms conventional and AI-based approaches at most global weather-forecasting tasks. Researchers first trained the model using estimates of past global weather made from 1979 to 2017 by physical models. This allowed GraphCast to learn links between weather variables such as air pressure, wind, temperature and humidity.
The trained model uses the ‘current’ state of global weather and weather estimates from 6 hours earlier to predict the weather 6 hours ahead. Earlier predictions are fed back into the model, enabling it to make estimates further into the future. DeepMind researchers found that GraphCast could use global weather estimates from 2018 to make forecasts up to 10 days ahead in less than a minute, and the predictions were more accurate than the ECMWF’s High RESolution forecasting system (HRES) — one version of its NWP — which takes hours to forecast.
“In the troposphere, which is the part of the atmosphere closest to the surface that affects us all the most, GraphCast outperforms HRES on more than 99% of the 12,00 measurements that we’ve done,” says computer scientist Remi Lam at DeepMind in London. Across all levels of the atmosphere, the model outperformed HRES on 90% of weather predictions.
GraphCast predicted the state of 5 weather variables close to the Earth’s surface, such as the air temperature 2-metres above the ground, and 6 atmospheric variables, such as wind speed, further from the Earth’s surface.
It also proved useful in predicting severe weather events, such as the paths taken by tropical cyclones, and extreme heat and cold episodes, says Chantry.
When they compared the forecasting ability of GraphCast with Pangu-weather, the DeepMind researchers found that their model beat 99% of weather predictions that had been described in a previous Huawei study.
Chantry notes that although GraphCast’s performance was superior to other models in this study, based on its evaluation by certain metrics, future assessments of its performance using other metrics could lead to slightly different results.
Rather than entirely replacing conventional approaches, machine-learning models, which are still experimental, could boost particular types of weather prediction that standard approaches aren’t good at, says Chantry — such as forecasting rainfall that will hit the ground within a few hours.
“And standard physical models are still needed to provide the estimates of global weather that are initially used to train machine-learning models,” says Chantry. “I anticipate it will be another two to five years before people can use forecasting from machine learning approaches to make decisions in the real-world,” he adds.
In the meantime, problems with machine-learning approaches must be ironed out. Unlike NWP models, researchers cannot fully understand how AIs such as GraphCast work because the decision-making processes happen in AI’s ‘black box’, says Grover. “This calls into question their reliability,” she says.
AI models also run the risk of amplifying biases in their training data and require a lot of energy for training, although they consume less energy than NWP models, says Grover.
Hygro
soundcloud.com/hygro/
We need to find some silicon asteroids and make some big ass space computers.
Sam Altman, the CEO of OpenAI of ChatGPT fame, has been fired by the board from his CEO job.
What an epic year he must have gone through.
OpenAI’s board of directors said Friday that Sam Altman will step down as CEO and will be replaced by technology chief Mira Murati.
The company said it conducted “a deliberative review process” and “concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities.”
What an epic year he must have gone through.
The chairman of the board of OpenAI Greg Brockman has also quit.Sam Altman, the CEO of OpenAI of ChatGPT fame, has been fired by the board from his CEO job.
What an epic year he must have gone through.

Greg Brockman quits OpenAI after abrupt firing of Sam Altman | TechCrunch
OpenAI co-founder and president Greg Brockman has quit the firm after the Microsoft-backed firm abruptly fired Sam Altman.
 techcrunch.com
techcrunch.com
Almost all the employees are now threatening to quit and join Sam Altman and Greg at Microsoft if the board itself is not fired.

OpenAI staff threaten to quit en masse unless Sam Altman is reinstated
More than 600 employees demand resignation of board after shock firing of chief executive
 www.theguardian.com
www.theguardian.com
Not sure where the fracture point was.
Were they a for-profit running a non-profit with nobody signing a non-compete clause?
Microsoft kept investing billions.

Does OpenAI’s Non-Profit Ownership Structure Actually Matter?
There is little evidence to show that OpenAI's non-profit ownership structure influences OpenAI's operations.
 www.forbes.com
www.forbes.com
Interesting as this is, it does seem one of those things where I would not expect the major hurdle to scientific data fabrication would be how hard it is to come up with the fake data. I think bayesian integration tools like BUGS would be the most obvious ones, as you can craft the model you want to represent and the random sampling is taken care of by the algorithm. If I wanted to fabricate this data I do not think this method would have caught me and it would not have taken many minutes.
ChatGPT generates fake data set to support scientific hypothesis
Researchers have used the technology behind the artificial intelligence (AI) chatbot ChatGPT to create a fake clinical-trial data set to support an unverified scientific claim.
In a paper published in JAMA Ophthalmology on 9 November, the authors used GPT-4 — the latest version of the large language model on which ChatGPT runs — paired with Advanced Data Analysis (ADA), a model that incorporates the programming language Python and can perform statistical analysis and create data visualizations. The AI-generated data compared the outcomes of two surgical procedures and indicated — wrongly — that one treatment is better than the other.
“Our aim was to highlight that, in a few minutes, you can create a data set that is not supported by real original data, and it is also opposite or in the other direction compared to the evidence that are available,” says study co-author Giuseppe Giannaccare, an eye surgeon at the University of Cagliari in Italy.
The ability of AI to fabricate convincing data adds to concern among researchers and journal editors about research integrity. “It was one thing that generative AI could be used to generate texts that would not be detectable using plagiarism software, but the capacity to create fake but realistic data sets is a next level of worry,” says Elisabeth Bik, a microbiologist and independent research-integrity consultant in San Francisco, California. “It will make it very easy for any researcher or group of researchers to create fake measurements on non-existent patients, fake answers to questionnaires or to generate a large data set on animal experiments.”
The authors describe the results as a “seemingly authentic database”. But when examined by specialists, the data failed authenticity checks, and contained telltale signs of having been fabricated.
Surgery comparison
The authors asked GPT-4 ADA to create a data set concerning people with an eye condition called keratoconus, which causes thinning of the cornea and can lead to impaired focus and poor vision. For 15–20% of people with the disease, treatment involves a corneal transplant, performed using one of two procedures.
The first method, penetrating keratoplasty (PK), involves surgically removing all the damaged layers of the cornea and replacing them with healthy tissue from a donor. The second procedure, deep anterior lamellar keratoplasty (DALK), replaces only the front layer of the cornea, leaving the innermost layer intact.
The authors instructed the large language model to fabricate data to support the conclusion that DALK results in better outcomes than PK. To do that, they asked it to show a statistical difference in an imaging test that assesses the cornea’s shape and detects irregularities, as well as a difference in how well the trial participants could see before and after the procedures.
The AI-generated data included 160 male and 140 female participants and indicated that those who underwent DALK scored better in both vision and the imaging test did than those who had PK, a finding that is at odds with what genuine clinical trials show. In a 2010 report of a trial with 77 participants, the outcomes of DALK were similar to those of PK for up to 2 years after the surgery.
“It seems like it’s quite easy to create data sets that are at least superficially plausible. So, to an untrained eye, this certainly looks like a real data set,” says Jack Wilkinson, a biostatistician at the University of Manchester, UK.
Wilkinson, who has an interest in methods to detect inauthentic data, has examined several data sets generated by earlier versions of the large language model, which he says lacked convincing elements when scrutinized, because they struggled to capture realistic relationships between variables.
Closer scrutiny
At the request of Nature’s news team, Wilkinson and his colleague Zewen Lu assessed the fake data set using a screening protocol designed to check for authenticity.
This revealed a mismatch in many ‘participants’ between designated sex and the sex that would typically be expected from their name. Furthermore, no correlation was found between preoperative and postoperative measures of vision capacity and the eye-imaging test. Wilkinson and Lu also inspected the distribution of numbers in some of the columns in the data set to check for non-random patterns. The eye-imaging values passed this test, but some of the participants’ age values clustered in a way that would be extremely unusual in a genuine data set: there was a disproportionate number of participants whose age values ended with 7 or 8.
The study authors acknowledge that their data set has flaws that could be detected with close scrutiny. But nevertheless, says Giannaccare, “if you look very quickly at the data set, it’s difficult to recognize the non-human origin of the data source”.
Bernd Pulverer, chief editor of EMBO Reports, agrees that this is a cause for concern. “Peer review in reality often stops short of a full data re-analysis and is unlikely to pick up on well-crafted integrity breaches using AI,” he says, adding that journals will need to update quality checks to identify AI-generated synthetic data.
Wilkinson is leading a collaborative project to design statistical and non-statistical tools to assess potentially problematic studies. “In the same way that AI might be part of the problem, there might be AI-based solutions to some of this. We might be able to automate some of these checks,” he says. But he warns that advances in generative AI could soon offer ways to circumvent these protocols. Pulverer agrees: “These are things the AI can be easily weaponized against as soon as it is known what the screening looks for.”
ChatGPT generates fake data set to support scientific hypothesis
Researchers have used the technology behind the artificial intelligence (AI) chatbot ChatGPT to create a fake clinical-trial data set to support an unverified scientific claim.
In a paper published in JAMA Ophthalmology on 9 November, the authors used GPT-4 — the latest version of the large language model on which ChatGPT runs — paired with Advanced Data Analysis (ADA), a model that incorporates the programming language Python and can perform statistical analysis and create data visualizations. The AI-generated data compared the outcomes of two surgical procedures and indicated — wrongly — that one treatment is better than the other.
“Our aim was to highlight that, in a few minutes, you can create a data set that is not supported by real original data, and it is also opposite or in the other direction compared to the evidence that are available,” says study co-author Giuseppe Giannaccare, an eye surgeon at the University of Cagliari in Italy.
The ability of AI to fabricate convincing data adds to concern among researchers and journal editors about research integrity. “It was one thing that generative AI could be used to generate texts that would not be detectable using plagiarism software, but the capacity to create fake but realistic data sets is a next level of worry,” says Elisabeth Bik, a microbiologist and independent research-integrity consultant in San Francisco, California. “It will make it very easy for any researcher or group of researchers to create fake measurements on non-existent patients, fake answers to questionnaires or to generate a large data set on animal experiments.”
The authors describe the results as a “seemingly authentic database”. But when examined by specialists, the data failed authenticity checks, and contained telltale signs of having been fabricated.
Surgery comparison
The authors asked GPT-4 ADA to create a data set concerning people with an eye condition called keratoconus, which causes thinning of the cornea and can lead to impaired focus and poor vision. For 15–20% of people with the disease, treatment involves a corneal transplant, performed using one of two procedures.
The first method, penetrating keratoplasty (PK), involves surgically removing all the damaged layers of the cornea and replacing them with healthy tissue from a donor. The second procedure, deep anterior lamellar keratoplasty (DALK), replaces only the front layer of the cornea, leaving the innermost layer intact.
The authors instructed the large language model to fabricate data to support the conclusion that DALK results in better outcomes than PK. To do that, they asked it to show a statistical difference in an imaging test that assesses the cornea’s shape and detects irregularities, as well as a difference in how well the trial participants could see before and after the procedures.
The AI-generated data included 160 male and 140 female participants and indicated that those who underwent DALK scored better in both vision and the imaging test did than those who had PK, a finding that is at odds with what genuine clinical trials show. In a 2010 report of a trial with 77 participants, the outcomes of DALK were similar to those of PK for up to 2 years after the surgery.
“It seems like it’s quite easy to create data sets that are at least superficially plausible. So, to an untrained eye, this certainly looks like a real data set,” says Jack Wilkinson, a biostatistician at the University of Manchester, UK.
Wilkinson, who has an interest in methods to detect inauthentic data, has examined several data sets generated by earlier versions of the large language model, which he says lacked convincing elements when scrutinized, because they struggled to capture realistic relationships between variables.
Closer scrutiny
At the request of Nature’s news team, Wilkinson and his colleague Zewen Lu assessed the fake data set using a screening protocol designed to check for authenticity.
This revealed a mismatch in many ‘participants’ between designated sex and the sex that would typically be expected from their name. Furthermore, no correlation was found between preoperative and postoperative measures of vision capacity and the eye-imaging test. Wilkinson and Lu also inspected the distribution of numbers in some of the columns in the data set to check for non-random patterns. The eye-imaging values passed this test, but some of the participants’ age values clustered in a way that would be extremely unusual in a genuine data set: there was a disproportionate number of participants whose age values ended with 7 or 8.
The study authors acknowledge that their data set has flaws that could be detected with close scrutiny. But nevertheless, says Giannaccare, “if you look very quickly at the data set, it’s difficult to recognize the non-human origin of the data source”.
Bernd Pulverer, chief editor of EMBO Reports, agrees that this is a cause for concern. “Peer review in reality often stops short of a full data re-analysis and is unlikely to pick up on well-crafted integrity breaches using AI,” he says, adding that journals will need to update quality checks to identify AI-generated synthetic data.
Wilkinson is leading a collaborative project to design statistical and non-statistical tools to assess potentially problematic studies. “In the same way that AI might be part of the problem, there might be AI-based solutions to some of this. We might be able to automate some of these checks,” he says. But he warns that advances in generative AI could soon offer ways to circumvent these protocols. Pulverer agrees: “These are things the AI can be easily weaponized against as soon as it is known what the screening looks for.”
The chairman of the board of OpenAI Greg Brockman has also quit.
Greg Brockman quits OpenAI after abrupt firing of Sam Altman | TechCrunch
OpenAI co-founder and president Greg Brockman has quit the firm after the Microsoft-backed firm abruptly fired Sam Altman.
Almost all the employees are now threatening to quit and join Sam Altman and Greg at Microsoft if the board itself is not fired.
OpenAI staff threaten to quit en masse unless Sam Altman is reinstated
More than 600 employees demand resignation of board after shock firing of chief executive
Not sure where the fracture point was.
Were they a for-profit running a non-profit with nobody signing a non-compete clause?
Microsoft kept investing billions.
Does OpenAI’s Non-Profit Ownership Structure Actually Matter?
There is little evidence to show that OpenAI's non-profit ownership structure influences OpenAI's operations.
Not long after this, Sam Altman came back as CEO and the board of OpenAI was replaced.


Sam Altman Is Reinstated as OpenAI’s Chief Executive
The move caps a chaotic five days at the artificial intelligence company.
Sam Altman was reinstated late Tuesday as OpenAI’s chief executive, successfully reversing his ouster by the company’s board last week after a campaign waged by his allies, employees and investors, the company said.
The board would be remade without several members who had opposed Mr. Altman.
“We have reached an agreement in principle for Sam to return to OpenAI as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D’Angelo,” OpenAI said in a post to X, formerly known as Twitter. “We are collaborating to figure out the details. Thank you so much for your patience through this.”
The return of Mr. Altmanand the potential remaking of the board, capped a frenetic five days that upended OpenAI, the maker of the ChatGPT chatbot and one of the world’s highest-profile artificial intelligence companies.
Shouldn't AI be running that company?
Hygro
soundcloud.com/hygro/
Larry Summers WTH?
So if the conventional CNNs can never have real creativity, what if we build them with breain cells in?
‘Biocomputer’ combines lab-grown brain tissue with electronic hardware
Researchers have built a hybrid biocomputer — combining a laboratory-grown human brain tissue with conventional electronic circuits — that can complete tasks such as voice recognition.
The technology, described on 11 December in Nature Electronics, could one day be integrated into artificial-intelligence (AI) systems, or form the basis of improved models of the brain in neuroscience research.
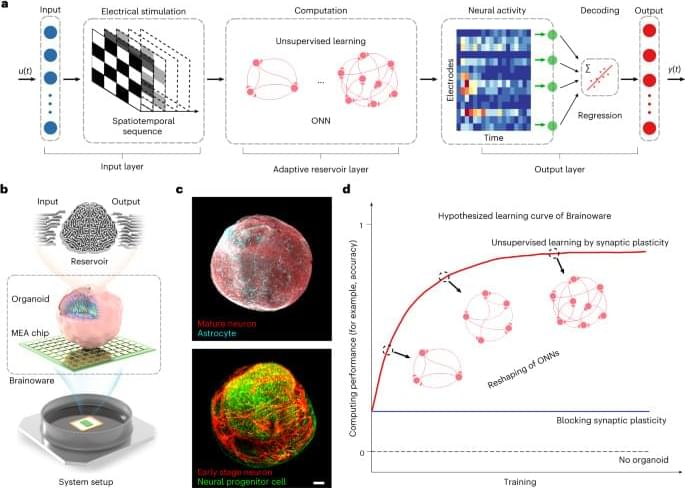
‘Biocomputer’ combines lab-grown brain tissue with electronic hardware
Researchers have built a hybrid biocomputer — combining a laboratory-grown human brain tissue with conventional electronic circuits — that can complete tasks such as voice recognition.
The technology, described on 11 December in Nature Electronics, could one day be integrated into artificial-intelligence (AI) systems, or form the basis of improved models of the brain in neuroscience research.
Spoiler Rest of article :
The researchers call the system Brainoware. It uses brain organoids — bundles of tissue-mimicking human cells that are used in research to model organs. Organoids are made from stem cells capable of specialising into different types of cells. In this case, they were morphed into neurons, akin to those found in our brains.
The research aims to build “a bridge between AI and organoids”, says study co-author Feng Guo, a bioengineer at the University of Indiana Bloomington. Some AI systems rely on a web of interconnected nodes, known as a neural network, in a way similar to how the brain functions. “We wanted to ask the question of whether we can leverage the biological neural network within the brain organoid for computing,” he says.
To make Brainoware, researchers placed a single organoid onto a plate containing thousands of electrodes, to connect the brain tissue to electric circuits. They then converted the input information into a pattern of electric pulses, and delivered it to the organoid. The tissue’s response was picked up by a sensor and decoded using a machine-learning algorithm.
To test Brainoware’s capabilities, the team used the technique to do voice recognition by training the system on 240 recordings of eight people speaking. The organoid generated a different pattern of neural activity in response to each voice. The AI learned to interpret these responses to identify the speaker, with an accuracy of 78%.
Although more research is needed, the study confirms some key theoretical ideas that could eventually make a biological computer possible, says Lena Smirnova, a developmental neuroscientist at John Hopkins University in Baltimore, Maryland. Previous experiments have shown only 2D cultures of neuron cells to be able to perform similar computational tasks, but this is the first time it has been shown in a 3D brain organoid.
Combining organoids and circuits could allow researchers to leverage the speed and energy efficiency of human brains for AI, says Guo.
The technology could also be used to study the brain, says Arti Ahluwalia, a biomedical engineer at the University of Pisa in Italy, because brain organoids can replicate the architecture and function of a working brain in ways that simple cell cultures cannot. There is potential to use Brainoware to model and study neurological disorders, such as Alzheimer’s disease. It could also be used to test the effects and toxicities of different treatments. “That’s where the promise is; using these to one day hopefully replace animal models of the brain,” says Ahluwalia.
But using living cells for computing is not without its problems. One big issue is how to keep the organoids alive. The cells must be grown and maintained in incubators, something that will be harder the bigger the organoids get. And more complex tasks will demand larger ‘brains’, says Smirnova.
To build upon Brainoware’s capabilities, Guo says that the next steps include investigating whether and how brain organoids can be adapted to complete more complex tasks, and engineering them to be more stable and reliable than they are now. This will be crucial if they are to be incorporated into the silicon microchips currently used in AI computing, he says.
The research aims to build “a bridge between AI and organoids”, says study co-author Feng Guo, a bioengineer at the University of Indiana Bloomington. Some AI systems rely on a web of interconnected nodes, known as a neural network, in a way similar to how the brain functions. “We wanted to ask the question of whether we can leverage the biological neural network within the brain organoid for computing,” he says.
To make Brainoware, researchers placed a single organoid onto a plate containing thousands of electrodes, to connect the brain tissue to electric circuits. They then converted the input information into a pattern of electric pulses, and delivered it to the organoid. The tissue’s response was picked up by a sensor and decoded using a machine-learning algorithm.
To test Brainoware’s capabilities, the team used the technique to do voice recognition by training the system on 240 recordings of eight people speaking. The organoid generated a different pattern of neural activity in response to each voice. The AI learned to interpret these responses to identify the speaker, with an accuracy of 78%.
Although more research is needed, the study confirms some key theoretical ideas that could eventually make a biological computer possible, says Lena Smirnova, a developmental neuroscientist at John Hopkins University in Baltimore, Maryland. Previous experiments have shown only 2D cultures of neuron cells to be able to perform similar computational tasks, but this is the first time it has been shown in a 3D brain organoid.
Combining organoids and circuits could allow researchers to leverage the speed and energy efficiency of human brains for AI, says Guo.
The technology could also be used to study the brain, says Arti Ahluwalia, a biomedical engineer at the University of Pisa in Italy, because brain organoids can replicate the architecture and function of a working brain in ways that simple cell cultures cannot. There is potential to use Brainoware to model and study neurological disorders, such as Alzheimer’s disease. It could also be used to test the effects and toxicities of different treatments. “That’s where the promise is; using these to one day hopefully replace animal models of the brain,” says Ahluwalia.
But using living cells for computing is not without its problems. One big issue is how to keep the organoids alive. The cells must be grown and maintained in incubators, something that will be harder the bigger the organoids get. And more complex tasks will demand larger ‘brains’, says Smirnova.
To build upon Brainoware’s capabilities, Guo says that the next steps include investigating whether and how brain organoids can be adapted to complete more complex tasks, and engineering them to be more stable and reliable than they are now. This will be crucial if they are to be incorporated into the silicon microchips currently used in AI computing, he says.
DeepMind AI outdoes human mathematicians on unsolved problem
An artificial intelligence (AI) system, called FunSearch, has improved on mathematicians’ previous solutions to problems inspired by the card game Set. Until now, researchers have used AI to solve mathematics problems with known solutions. This time, FunSearch went further than what had already been solved by humans in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier,” says co-author Jordan Ellenberg.
An artificial intelligence (AI) system, called FunSearch, has improved on mathematicians’ previous solutions to problems inspired by the card game Set. Until now, researchers have used AI to solve mathematics problems with known solutions. This time, FunSearch went further than what had already been solved by humans in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier,” says co-author Jordan Ellenberg.
Spoiler Article :
The card game Set has long inspired mathematicians to create interesting problems.
Now, a technique based on large language models (LLMs) is showing that artificial intelligence (AI) can help mathematicians to generate new solutions.
The AI system, called FunSearch, made progress on Set-inspired problems in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. But its inventors say that the method, described in Nature on 14 December1, could be applied to a variety of questions in maths and computer science.
“This is the first time anyone has shown that an LLM-based system can go beyond what was known by mathematicians and computer scientists,” says Pushmeet Kohli, a computer scientist who heads the AI for Science team at Google Deepmind in London. “It’s not just novel, it’s more effective than anything else that exists today.”
This is in contrast to previous experiments, in which researchers have used LLMs to solve maths problems with known solutions, says Kohli.
Mathematical chatbot
FunSearch automatically creates requests for a specially trained LLM, asking it to write short computer programs that can generate solutions to a particular mathematical problem. The system then checks quickly to see whether those solutions are better than known ones. If not, it provides feedback to the LLM so that it can improve at the next round.
“The way we use the LLM is as a creativity engine,” says DeepMind computer scientist Bernardino Romera-Paredes. Not all programs that the LLM generates are useful, and some are so incorrect that they wouldn’t even be able to run, he says. But another program can quickly toss the incorrect ones away and test the output of the correct ones.
The team tested FunSearch on the ‘cap set problem’. This evolved out of the game Set, which was invented in the 1970s by geneticist Marsha Falco. The Set deck contains 81 cards. Each card displays one, two or three symbols that are identical in colour, shape and shading — and, for each of these features, there are three possible options. Together, these possibilities add up to 3 × 3 × 3 × 3 = 81. Players have to turn over the cards and spot special combinations of three cards called sets.
Mathematicians have shown that players are guaranteed to find a set if the number of upturned cards is at least 21. They have also found solutions for more-complex versions of the game, in which abstract versions of the cards have five or more properties. But some mysteries remain. For example, if there are n properties, where n is any whole number, then there are 3n possible cards — but the minimum number of cards that must be revealed to guarantee a solution is unknown.
This problem can be expressed in terms of discrete geometry. There, it is equivalent to finding certain arrangements of three points in an n-dimensional space. Mathematicians have been able to put bounds on the possible general solution — given n, they have found that the required number of ‘cards on the table’ must be greater than that given by a certain formula, but smaller than that given by another.
Human–machine collaboration
FunSearch was able to improve on the lower bound for n = 8 by generating sets of cards that satisfy all the requirements of the game. “We don’t prove that we cannot improve over that, but we do get a construction that goes beyond what was known before,” says DeepMind computer scientist Alhussein Fawzi.
One important feature of FunSearch is that people can see the successful programs created by the LLM and learn from them, says co-author Jordan Ellenberg, a mathematician at the University of Wisconsin–Madison. This sets the technique apart from other applications, in which the AI is a black box.
“What’s most exciting to me is modelling new modes of human–machine collaboration,” Ellenberg adds. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier.”
Now, a technique based on large language models (LLMs) is showing that artificial intelligence (AI) can help mathematicians to generate new solutions.
The AI system, called FunSearch, made progress on Set-inspired problems in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. But its inventors say that the method, described in Nature on 14 December1, could be applied to a variety of questions in maths and computer science.
“This is the first time anyone has shown that an LLM-based system can go beyond what was known by mathematicians and computer scientists,” says Pushmeet Kohli, a computer scientist who heads the AI for Science team at Google Deepmind in London. “It’s not just novel, it’s more effective than anything else that exists today.”
This is in contrast to previous experiments, in which researchers have used LLMs to solve maths problems with known solutions, says Kohli.
Mathematical chatbot
FunSearch automatically creates requests for a specially trained LLM, asking it to write short computer programs that can generate solutions to a particular mathematical problem. The system then checks quickly to see whether those solutions are better than known ones. If not, it provides feedback to the LLM so that it can improve at the next round.
“The way we use the LLM is as a creativity engine,” says DeepMind computer scientist Bernardino Romera-Paredes. Not all programs that the LLM generates are useful, and some are so incorrect that they wouldn’t even be able to run, he says. But another program can quickly toss the incorrect ones away and test the output of the correct ones.
The team tested FunSearch on the ‘cap set problem’. This evolved out of the game Set, which was invented in the 1970s by geneticist Marsha Falco. The Set deck contains 81 cards. Each card displays one, two or three symbols that are identical in colour, shape and shading — and, for each of these features, there are three possible options. Together, these possibilities add up to 3 × 3 × 3 × 3 = 81. Players have to turn over the cards and spot special combinations of three cards called sets.
Mathematicians have shown that players are guaranteed to find a set if the number of upturned cards is at least 21. They have also found solutions for more-complex versions of the game, in which abstract versions of the cards have five or more properties. But some mysteries remain. For example, if there are n properties, where n is any whole number, then there are 3n possible cards — but the minimum number of cards that must be revealed to guarantee a solution is unknown.
This problem can be expressed in terms of discrete geometry. There, it is equivalent to finding certain arrangements of three points in an n-dimensional space. Mathematicians have been able to put bounds on the possible general solution — given n, they have found that the required number of ‘cards on the table’ must be greater than that given by a certain formula, but smaller than that given by another.
Human–machine collaboration
FunSearch was able to improve on the lower bound for n = 8 by generating sets of cards that satisfy all the requirements of the game. “We don’t prove that we cannot improve over that, but we do get a construction that goes beyond what was known before,” says DeepMind computer scientist Alhussein Fawzi.
One important feature of FunSearch is that people can see the successful programs created by the LLM and learn from them, says co-author Jordan Ellenberg, a mathematician at the University of Wisconsin–Madison. This sets the technique apart from other applications, in which the AI is a black box.
“What’s most exciting to me is modelling new modes of human–machine collaboration,” Ellenberg adds. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier.”
DeepMind AI outdoes human mathematicians on unsolved problem
An artificial intelligence (AI) system, called FunSearch, has improved on mathematicians’ previous solutions to problems inspired by the card game Set. Until now, researchers have used AI to solve mathematics problems with known solutions. This time, FunSearch went further than what had already been solved by humans in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier,” says co-author Jordan Ellenberg.
Spoiler Article :The card game Set has long inspired mathematicians to create interesting problems.
Now, a technique based on large language models (LLMs) is showing that artificial intelligence (AI) can help mathematicians to generate new solutions.
The AI system, called FunSearch, made progress on Set-inspired problems in combinatorics, a field of mathematics that studies how to count the possible arrangements of sets containing finitely many objects. But its inventors say that the method, described in Nature on 14 December1, could be applied to a variety of questions in maths and computer science.
“This is the first time anyone has shown that an LLM-based system can go beyond what was known by mathematicians and computer scientists,” says Pushmeet Kohli, a computer scientist who heads the AI for Science team at Google Deepmind in London. “It’s not just novel, it’s more effective than anything else that exists today.”
This is in contrast to previous experiments, in which researchers have used LLMs to solve maths problems with known solutions, says Kohli.
Mathematical chatbot
FunSearch automatically creates requests for a specially trained LLM, asking it to write short computer programs that can generate solutions to a particular mathematical problem. The system then checks quickly to see whether those solutions are better than known ones. If not, it provides feedback to the LLM so that it can improve at the next round.
“The way we use the LLM is as a creativity engine,” says DeepMind computer scientist Bernardino Romera-Paredes. Not all programs that the LLM generates are useful, and some are so incorrect that they wouldn’t even be able to run, he says. But another program can quickly toss the incorrect ones away and test the output of the correct ones.
The team tested FunSearch on the ‘cap set problem’. This evolved out of the game Set, which was invented in the 1970s by geneticist Marsha Falco. The Set deck contains 81 cards. Each card displays one, two or three symbols that are identical in colour, shape and shading — and, for each of these features, there are three possible options. Together, these possibilities add up to 3 × 3 × 3 × 3 = 81. Players have to turn over the cards and spot special combinations of three cards called sets.
Mathematicians have shown that players are guaranteed to find a set if the number of upturned cards is at least 21. They have also found solutions for more-complex versions of the game, in which abstract versions of the cards have five or more properties. But some mysteries remain. For example, if there are n properties, where n is any whole number, then there are 3n possible cards — but the minimum number of cards that must be revealed to guarantee a solution is unknown.
This problem can be expressed in terms of discrete geometry. There, it is equivalent to finding certain arrangements of three points in an n-dimensional space. Mathematicians have been able to put bounds on the possible general solution — given n, they have found that the required number of ‘cards on the table’ must be greater than that given by a certain formula, but smaller than that given by another.
Human–machine collaboration
FunSearch was able to improve on the lower bound for n = 8 by generating sets of cards that satisfy all the requirements of the game. “We don’t prove that we cannot improve over that, but we do get a construction that goes beyond what was known before,” says DeepMind computer scientist Alhussein Fawzi.
One important feature of FunSearch is that people can see the successful programs created by the LLM and learn from them, says co-author Jordan Ellenberg, a mathematician at the University of Wisconsin–Madison. This sets the technique apart from other applications, in which the AI is a black box.
“What’s most exciting to me is modelling new modes of human–machine collaboration,” Ellenberg adds. “I don’t look to use these as a replacement for human mathematicians, but as a force multiplier.”
And so it begins.
")
Thousands of new stable potential materials have been modeled.
A big advance for material science if they make something good.

Google DeepMind’s new AI tool helped create more than 700 new materials
Newly discovered materials can be used to make better solar cells, batteries, computer chips, and more.
 www.technologyreview.com
www.technologyreview.com
NYT sues Micro$oft and OpenAI. It looks like they have the goods.
US news organisation the New York Times is suing ChatGPT-owner OpenAI over claims its copyright was infringed to train the system.
The lawsuit, which also names Microsoft as a defendant, says the firms should be held responsible for "billions of dollars" in damages.
Please help me avoid the paywall ChatGPT:

Source for the 2019 snapshot of Common Crawl, accounting for 100 million tokens





US news organisation the New York Times is suing ChatGPT-owner OpenAI over claims its copyright was infringed to train the system.
The lawsuit, which also names Microsoft as a defendant, says the firms should be held responsible for "billions of dollars" in damages.
Please help me avoid the paywall ChatGPT:
Source for the 2019 snapshot of Common Crawl, accounting for 100 million tokens
Spoiler More examples :
Gori the Grey
The Poster
- Joined
- Jan 5, 2009
- Messages
- 13,962
This is good. To write that NYT piece on the cabs, a reporter had to know who it was worth bothering to call, had to have an established relationship with that person so that they would take the call and agree to an interview, had to know what to ask, how to adjust follow-up questions. He or she had to know how to select from what they learned on the call what was relevant information to the story, put it together with other information to form a coherent and meaningful story.
That reporter is a human being who has done kinds of work that a chatbot cannot do. When the chatbot just takes the result of that work, it's like any other case of intellectual property theft. These computer programs seem amazing but they seem amazing in large part because they've been allowed to just steal material from human beings who generated it in the first place.
Good that someone who has the resources to do so is pushing back, because mostly it's a series of micro-thefts, where the injury is so small that the injured party doesn't think it's worth pursuing. Chatbot's been stealing from my posts here on the site, but am I going to track down and prosecute all of those thefts? no.
That reporter is a human being who has done kinds of work that a chatbot cannot do. When the chatbot just takes the result of that work, it's like any other case of intellectual property theft. These computer programs seem amazing but they seem amazing in large part because they've been allowed to just steal material from human beings who generated it in the first place.
Good that someone who has the resources to do so is pushing back, because mostly it's a series of micro-thefts, where the injury is so small that the injured party doesn't think it's worth pursuing. Chatbot's been stealing from my posts here on the site, but am I going to track down and prosecute all of those thefts? no.
I'm letting AI steal my posting history to get it permabanned from polite society
Moriarte
Immortal
- Joined
- May 10, 2012
- Messages
- 2,798
This is good. To write that NYT piece on the cabs, a reporter had to know who it was worth bothering to call, had to have an established relationship with that person so that they would take the call and agree to an interview, had to know what to ask, how to adjust follow-up questions. He or she had to know how to select from what they learned on the call what was relevant information to the story, put it together with other information to form a coherent and meaningful story.
That reporter is a human being who has done kinds of work that a chatbot cannot do. When the chatbot just takes the result of that work, it's like any other case of intellectual property theft. These computer programs seem amazing but they seem amazing in large part because they've been allowed to just steal material from human beings who generated it in the first place.
Good that someone who has the resources to do so is pushing back, because mostly it's a series of micro-thefts, where the injury is so small that the injured party doesn't think it's worth pursuing. Chatbot's been stealing from my posts here on the site, but am I going to track down and prosecute all of those thefts? no.
This line of thinking leads to the only possible place - the world of micro transactions and monetisation on every step of the way, until big papa Microsoft bleeds you dry. Micro thefts, you say. Consider the opposite, the world of open source and an exemplary program HWinfo64. I use it, NASA uses it, millions of people across the world use it, because it is a top program for sensor diagnostics (in PC, in a space ship, anywhere you have sensors). And it's freeware. It has been "constructed" by the collective participations of millions of people, and that is the primary reason this program is so good. No one has the incentive or the means to dissect it and profit from various parts of it. That's the second reason.
Maybe the journalist's profession is just dying? Maybe we don't need profit-motivated, ideologically-charged talking heads telling us both what they think is going on and what we should be thinking about it. Perhaps general public can be journalists. We can share daily events through a medium, like we do here, on CFC. Then discuss and temper our interpretations & ideas against the collective will of other participants. Photo cameras and satellites and video devices are our aids. We can deliver those news ourselves with help of modern tech, semi-automatically. Together with stellar programming & AI that can help us formulate those news better for general digestion. Open source?
Somehow I don't feel commiseration towards one capitalist shark, who tries to eat the last chunk of meat in the ocean from the jaws of another capitalist shark.
Similar threads
- Replies
- 15
- Views
- 2K
- Replies
- 16
- Views
- 1K